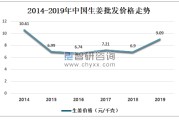
标题:应用大数据查询技术解决姜产业相关问题简介:大数据查询技术是一种利用现代计算机技术和算法,对庞大的数据集进行高效、准确、实时查询和分析的方法。在姜...
Impala大数据查询
生活
2024年04月16日 05:35 827
admin
Impala是一个开源的、高性能的SQL查询引擎,专门用于在Apache Hadoop上进行交互式查询。它允许用户使用标准的SQL语法来查询存储在Hadoop集群中的数据,而无需移动数据或进行复杂的ETL过程。以下是关于Impala大数据查询的一些重要信息和指导:
1. 数据模型设计
在进行Impala查询之前,首先需要设计合适的数据模型。数据模型设计应考虑数据的组织方式、表之间的关系以及查询需求。合理的数据模型设计可以提高查询性能和效率。
2. 数据格式
Impala支持多种数据格式,包括Parquet、Avro、ORC等。选择合适的数据格式可以减少存储空间占用和提高查询性能。通常推荐使用Parquet格式,因为它具有高效的压缩和列式存储特性。
3. 分区和分桶
通过对数据进行分区和分桶可以进一步提高查询性能。分区可以将数据按照指定的列进行分组,减少查询时需要扫描的数据量;分桶可以将数据分散存储在多个文件中,提高并行查询的效率。
4. SQL查询优化
在编写SQL查询时,可以采取一些优化措施来提高查询性能,例如避免使用SELECT *、合理使用JOIN操作、使用LIMIT限制返回结果数量等。可以通过查看查询计划和执行统计信息来优化查询。
5. 数据安全
在进行Impala查询时,需要注意数据安全性。可以通过权限管理、加密传输等方式保护数据的安全。及时备份数据也是保障数据安全的重要措施。
6. 性能调优
对于大数据查询,性能调优是至关重要的。可以通过调整Impala配置参数、增加集群资源、优化查询语句等方式来提高查询性能。定期监控集群性能并进行调优是保持查询效率的关键。
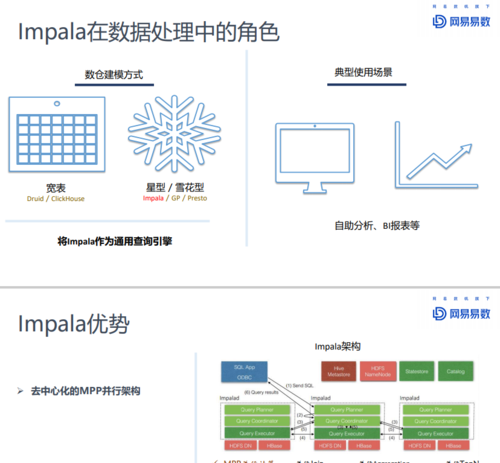
7. 数据可视化
最终用户通常希望以可视化的方式呈现查询结果。可以使用BI工具如Tableau、Power BI等将Impala查询结果可视化展示,帮助用户更直观地理解数据。
Impala作为一款强大的大数据查询工具,可以帮助用户快速、高效地分析海量数据。通过合理的数据模型设计、优化查询语句、性能调优等措施,可以充分发挥Impala的优势,实现更好的查询效果。