Title: An Overview of Big Data Distribution Analysis in SQL
Big data distribution analysis in SQL involves handling massive volumes of data distributed across various nodes or servers in a distributed computing environment. This process requires efficient SQL queries and techniques to extract meaningful insights from distributed data sets. Let's delve into the key aspects of big data distribution analysis in SQL.
Understanding Big Data Distribution:
In a distributed computing environment, big data is typically stored across multiple nodes or servers. Each node contains a subset of the overall data set, and the data is distributed based on certain criteria such as partition keys or hashing algorithms. This distribution strategy aims to improve performance and scalability by parallelizing data processing tasks across multiple nodes.
Challenges in Big Data Distribution Analysis:
1.
Data Skew:
Nonuniform distribution of data across nodes can lead to data skew, where certain nodes process significantly more data than others. This imbalance can result in performance bottlenecks and uneven resource utilization.
2.
Network Overhead:
Analyzing distributed data involves transferring data between nodes over the network, which can incur overhead and impact query performance, especially in geographically dispersed environments.
3.
Complex Joins:
Joining data across distributed tables requires coordination and communication between nodes, making it challenging to optimize query execution plans for efficient join operations.
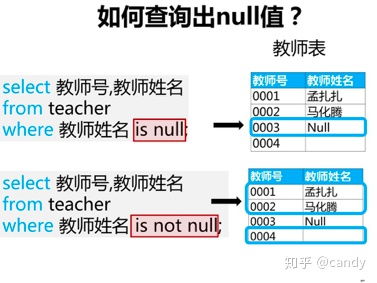
Techniques for Big Data Distribution Analysis in SQL:
1.
Partitioning Strategies:
Utilize SQL partitioning techniques such as range partitioning, hash partitioning, or list partitioning to distribute data evenly across nodes based on specific criteria. This helps mitigate data skew and improve query performance by minimizing data movement during analysis.
2.
Parallel Processing:
Leverage SQL features such as parallel query execution to distribute query workload across multiple nodes simultaneously. This allows for parallel processing of data partitions, reducing query latency and improving overall throughput.
3.
Data Replication:
Consider replicating frequently accessed data across multiple nodes to improve data locality and reduce network overhead during analysis. Replication can enhance fault tolerance and query performance by enabling data retrieval from the nearest replica.
4.
Query Optimization:
Optimize SQL queries for distributed environments by minimizing data shuffling and reducing the number of network roundtrips. Techniques such as query pruning, predicate pushdown, and index optimization can improve query performance and resource utilization.
5.
Distributed Joins:
Use distributed join algorithms such as broadcast join or partitioned join to efficiently join data across distributed tables. These algorithms minimize data movement by replicating smaller tables or partitioning larger tables for join operations.
Best Practices for Big Data Distribution Analysis:
1.
Data Sampling:
Prioritize data sampling techniques to analyze representative subsets of distributed data before performing fullscale analysis. Sampling helps identify data distribution patterns, outliers, and potential performance issues early in the analysis process.
2.
Monitoring and Optimization:
Continuously monitor query performance, resource utilization, and data distribution metrics to identify bottlenecks and optimize SQL queries accordingly. Regular performance tuning and optimization are essential for maintaining efficient big data analysis workflows.
3.
Scalability and Elasticity:
Design SQL queries and data processing pipelines to scale horizontally with the addition of new nodes or resources. Embrace cloudbased solutions and elastic computing platforms to dynamically scale infrastructure based on workload demands and resource availability.
4.
Fault Tolerance:
Implement faulttolerant SQL solutions with builtin mechanisms for data replication, backup, and recovery to ensure data integrity and availability in distributed environments. Plan for failure scenarios and design resilient data processing pipelines to minimize downtime and data loss.
Conclusion:
Big data distribution analysis in SQL requires a combination of distributed computing principles, SQL optimization techniques, and best practices for efficient data processing and analysis. By understanding the challenges associated with distributed data environments and adopting appropriate strategies and best practices, organizations can derive valuable insights and make informed decisions from their big data assets.