大数据的结构类型有哪些
Understanding the Basic Structure of Big Data
Big Data refers to massive volumes of structured, semistructured, and unstructured data that is generated at an unprecedented rate in today's digital world. To effectively manage and derive insights from this vast amount of data, it's essential to understand its basic structure.
The first characteristic of big data is its sheer volume. Traditional data processing systems struggle to handle the massive amounts of data generated daily. This includes data from social media interactions, online transactions, sensor data, and more. The volume of data is measured in terabytes, petabytes, exabytes, and beyond.
Big data comes in various forms, including structured, semistructured, and unstructured data. Structured data is highly organized and easily searchable, such as data stored in databases and spreadsheets. Semistructured data lacks a formal structure but contains tags or other markers to separate elements and hierarchies, like XML files or JSON. Unstructured data, on the other hand, lacks any specific format and includes text documents, emails, videos, images, social media posts, etc.
The velocity of big data refers to the speed at which data is generated, collected, and processed. With the rise of the Internet of Things (IoT), sensors, and other devices, data is generated in realtime. This constant stream of data requires systems capable of processing and analyzing it rapidly to extract meaningful insights in a timely manner.
Veracity refers to the quality and reliability of the data. Big data often comes from diverse sources, and not all of it may be accurate or trustworthy. Data may contain errors, inconsistencies, or even deliberate distortions. Ensuring data quality is crucial for making informed decisions and deriving accurate insights.
The ultimate goal of big data is to derive value from the insights gained through its analysis. By harnessing the power of big data analytics, organizations can uncover hidden patterns, trends, and correlations that can lead to better decisionmaking, improved efficiency, and competitive advantages.
Big data can exhibit variability in terms of its structure, format, and meaning. The same data may be interpreted differently depending on the context in which it is used or the analytical techniques applied. Managing this variability is essential for ensuring consistency and accuracy in data analysis.
Visualization plays a crucial role in big data analysis by presenting complex datasets in a visual format that is easy to understand and interpret. Data visualization techniques, such as charts, graphs, and dashboards, help analysts identify patterns, trends, and outliers, enabling them to make datadriven decisions effectively.
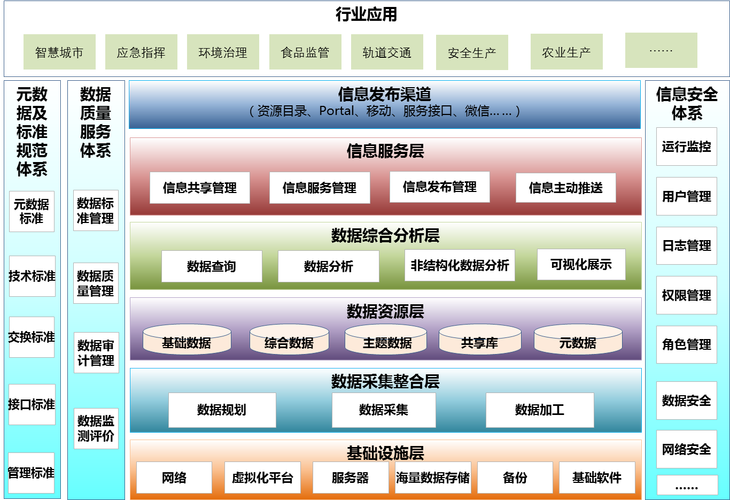
Understanding the basic structure of big data is essential for organizations seeking to leverage its potential for gaining insights and driving innovation. By addressing the volume, variety, velocity, veracity, value, variability, and visualization aspects of big data, businesses can unlock new opportunities and stay competitive in today's datadriven world.