大数据分布式处理怎么理解
大数据分布式数据架构概述及其重要性
概述:
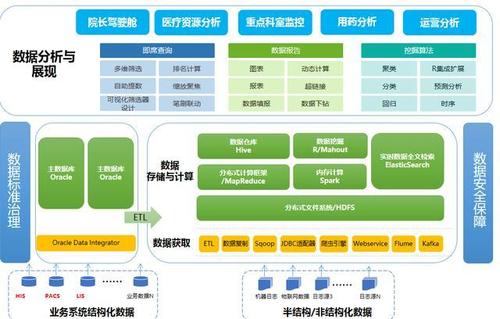
大数据分布式数据架构是指在大数据环境下,将数据分布式地存储和处理的一种架构设计。它通过将数据分散存储于多个节点上,并利用并行计算的方式进行数据处理和分析,以实现高性能和高可扩展性。分布式数据架构充分利用了集群中的计算和存储资源,能够处理海量数据并快速进行数据挖掘、分析和决策支持。
重要性:
1. 处理海量数据:传统的单机架构面对海量数据处理时往往性能低下,而分布式数据架构能够有效地提高数据处理的速度和效率,满足大数据场景下的需求。
2. 高可扩展性:随着数据规模增长的需要,分布式数据架构可以方便地通过增加节点来扩展存储和计算能力,使系统能够适应不断增长的数据负载的变化。
3. 容错性:分布式数据架构将数据存储在多个节点上,相比于单机架构具备更高的容错性。在某个节点失败时,系统可以自动切换到其他正常的节点,保证数据的正常处理和服务的连续性。
4. 实时性:分布式数据架构支持并行计算和实时处理,可以满足实时分析和决策的需求。对于需要快速响应的业务场景,分布式数据架构具备一定的优势。
建议:
设计和实现一个高效的分布式数据架构需要考虑以下几个方面:
1. 数据划分和复制策略:合理地将数据划分为不同的分区,并选择适当的复制策略来提高系统的可用性和容错性。常见的数据划分策略有哈希划分、范围划分等,而复制策略可以选择主从复制、多主复制等。
2. 数据分布和负载均衡:根据数据的访问模式和负载情况,合理地将数据分布于各个节点,并实现负载均衡策略以提高系统的整体性能。常见的负载均衡策略有轮询、随机等。
3. 数据一致性和事务管理:在分布式环境下,保证数据的一致性是一个重要的挑战。可以引入分布式事务管理机制,如基于2PC或3PC的方案,来保证数据的一致性和正确性。
4. 故障检测和容错恢复:建议在架构设计中考虑节点故障的检测和容错恢复机制,及时发现和处理异常节点,保证系统的可用性。常见的技术包括心跳检测、故障转移等。
5. 选择合适的分布式计算框架:根据具体的业务场景和需求,选择合适的分布式计算框架,如Apache Hadoop、Apache Spark等,来进行数据处理和分析。
大数据分布式数据架构是处理和分析海量数据的关键技术之一。它通过将数据分散存储和处理,提高了系统的性能、可扩展性和容错性。在设计和实现分布式数据架构时,需要考虑数据划分、负载均衡、数据
标签: 大数据分布式数据架构是什么 大数据分布式处理怎么理解 分布式大数据分析
相关文章