flume采集数据会丢失吗
常识
2024年05月07日 17:10 694
admin
Flume大数据收集
Flume是Apache软件基金会的一个可靠、可扩展的分布式系统,用于收集、聚合和移动大量数据。它在大数据生态系统中扮演着重要的角色,用于实时收集、传输和处理大规模数据。
Flume的工作原理是基于事件流的。它由三个主要组件组成:
Flume的数据流动方式可以通过配置来定义,例如,从源到通道的数据流动方式、从通道到下沉器的数据流动方式等。这使得用户可以根据需求灵活地配置数据的流动路径。
Flume广泛应用于大数据领域,其主要应用场景包括:
- 日志收集:Flume可以实时收集分布式系统或应用程序产生的日志数据,并将其发送到集中式存储或分析系统中进行分析和处理。
- 数据聚合:Flume可以从多个数据源收集数据,并将其聚合到一个目标位置,以便进行进一步的分析和报告。
- 事件处理:Flume可以捕获和处理事件流,例如社交媒体数据、传感器数据等。
- 数据传输:Flume可以将数据从一个位置传输到另一个位置,例如将数据从一个集群传输到另一个集群。
以下是使用Flume时的一些建议:
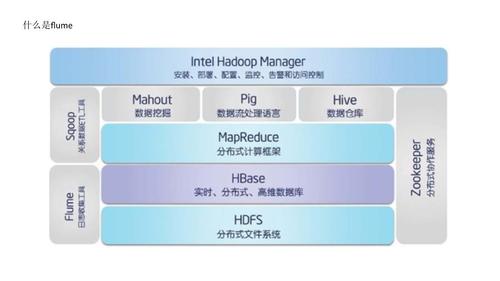
Flume是一个强大的工具,用于大规模数据的收集、传输和处理。合理使用Flume可以提高数据收集和处理的效率,为大数据分析提供有力支持。
标签: flume采集数据到hdfs flume收集日志的多种方式 flume采集 flume数据采集架构框架图 flume数据采集工具
相关文章