**大同大数据开源优势**大数据技术的发展已经成为许多行业解决问题和推动创新的重要工具。在这个领域,大同大数据(ApacheHadoop)作为一个开源...
2024-04-27 783 大数据开源框架有哪些 大同大数据中心招聘网最新招聘 开源大数据平台hadoop 大同大数据
大数据开源软件是当今信息技术领域中的重要组成部分,它们为企业和组织处理、存储和分析海量数据提供了强大的工具和平台。以下是对几种主要的大数据开源软件的分析和指导建议:
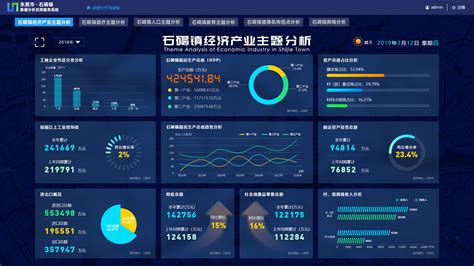
大数据开源软件为企业提供了处理和分析海量数据的能力,但在选择和使用时需根据具体场景和需求进行合理选择。建议企业在引入这些开源软件时,充分评估自身业务需求,进行技术调研和评估,培训相关技术人员,以构建数据驱动型业务,实现业务增长和竞争优势。
标签: 大数据开源软件哪个好 大数据开源软件有哪些 大数据开源框架有哪些 大数据开发的软件
相关文章
**大同大数据开源优势**大数据技术的发展已经成为许多行业解决问题和推动创新的重要工具。在这个领域,大同大数据(ApacheHadoop)作为一个开源...
2024-04-27 783 大数据开源框架有哪些 大同大数据中心招聘网最新招聘 开源大数据平台hadoop 大同大数据
大数据开发是指通过各种技术手段来处理海量数据,从中发现有价值的信息并进行分析的过程。在大数据开发过程中,有一些常用的公式和技术方法可以帮助开发人员更高...
2024-04-26 223 大数据开发的软件 大数据开发前景如何 大数据开发框架有哪些 大数据开发主要学什么

大数据技术在企业中的应用越来越广泛,开源工具在这一领域也扮演着重要的角色。以下是一些企业常用的大数据开源工具:1.ApacheHadoopApache...
2024-04-14 181 大数据开源框架有哪些 企业大数据种类来源 企业大数据平台 企业大数据开源有哪些类型 企业大数据bi