在大数据分析领域,准确性是一个至关重要的指标。大数据分析通过对海量数据的收集、处理和分析,可以帮助企业或组织做出正确的决策,发现潜在的趋势和模式。然而...
2024-04-29 608 大数据分数查询 大数据分高好还是分低好 大数据分太低怎么办 大数据的分数是什么意思 大数据分越低越好吗
In the realm of big data, the efficiency of queries is paramount to extract valuable insights and drive informed decisionmaking. To achieve optimal performance in querying large datasets, several key factors need consideration. Let's delve into them:
Efficient querying begins with robust data indexing. Indexes organize data in a structured manner, allowing databases to locate information swiftly. Techniques like Btree, Hashing, and Bitmap Indexing optimize data retrieval. Utilizing appropriate indexing strategies tailored to the dataset's characteristics significantly enhances query speed.
Partitioning involves dividing large datasets into smaller, manageable segments distributed across nodes or servers. Partitioning strategies such as Range, Hash, or List partitioning enable parallel processing, reducing query execution time. Effective partitioning ensures balanced data distribution and prevents hotspots, thus improving query performance.
Query optimization involves refining SQL queries to minimize resource consumption and execution time. Techniques like query rewriting, join optimization, and subquery optimization streamline query execution plans. Additionally, employing appropriate indexing hints and utilizing query analyzers can further enhance performance.
Leveraging distributed processing frameworks like Apache Hadoop or Apache Spark enables parallel execution of queries across multiple nodes or clusters. Distributed processing harnesses the combined computational power of interconnected machines, accelerating query processing for immense datasets.
Implementing caching mechanisms reduces redundant computations by storing frequently accessed data in memory. Utilizing inmemory databases (IMDB) or caching frameworks like Redis or Memcached accelerates query response times, especially for recurrent queries or realtime analytics.
Data compression techniques minimize storage requirements and enhance query performance by reducing disk I/O operations. Employing compression algorithms like LZ77, Huffman Coding, or Snappy optimizes storage utilization and expedites data retrieval.
Optimizing hardware infrastructure, including CPU, memory, and storage components, is crucial for query performance. Investing in highperformance servers, SSD storage, and memory optimization techniques like sharding or replication ensures swift data access and processing.
Continuously monitoring query performance and profiling execution plans help identify bottlenecks and inefficiencies. Utilizing query profiling tools and performance monitoring dashboards facilitates proactive optimization, ensuring queries operate at peak efficiency.
Parallelizing query execution and implementing pipeline processing techniques expedite data retrieval and processing. Breaking down queries into smaller tasks and executing them concurrently enhances throughput and reduces query latency.
Denormalizing data structures by aggregating or precomputing results eliminates the need for complex joins and computations during querying. Precomputed summary tables or materialized views provide denormalized data representations, accelerating query performance.

In conclusion, maximizing efficiency in big data queries necessitates a holistic approach encompassing data indexing, partitioning, query optimization, distributed processing, caching, compression, hardware optimization, query tuning, parallelization, and data denormalization. By implementing these strategies judiciously and continuously refining them based on evolving requirements, organizations can unlock the full potential of their big data infrastructure and derive actionable insights effectively.
标签: 大数据查询20分 大数据查询55分什么意思 大数据分数查询
相关文章
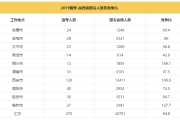
在大数据分析领域,准确性是一个至关重要的指标。大数据分析通过对海量数据的收集、处理和分析,可以帮助企业或组织做出正确的决策,发现潜在的趋势和模式。然而...
2024-04-29 608 大数据分数查询 大数据分高好还是分低好 大数据分太低怎么办 大数据的分数是什么意思 大数据分越低越好吗