打造大数据平台生态圈随着信息化时代的不断发展,大数据已经成为企业发展的重要驱动力之一。打造大数据平台生态圈是企业实现数据资产最大化利用的关键一环。本文...
2024-05-19 347 大数据生态圈组件 大数据平台构建的意义 打造全国统一大数据平台
在当今信息时代,大数据已经成为许多行业发展的关键驱动力。大数据生态环境由多个组件构成,这些组件相互配合,形成了一个庞大而复杂的系统,用于收集、存储、处理和分析海量数据。本文将对大数据生态环境的主要组件进行解析,并提供相应的指导建议,帮助您更好地理解和应用大数据技术。
数据采集是大数据处理的第一步,它涉及从各种来源收集数据并将其传输到处理系统中。主要的数据采集组件包括:
大数据存储组件负责有效地存储大规模的数据,并提供高可靠性和可扩展性。常用的数据存储组件包括:
数据处理与计算组件用于对大规模数据进行分析、挖掘和计算。常见的数据处理与计算组件包括:
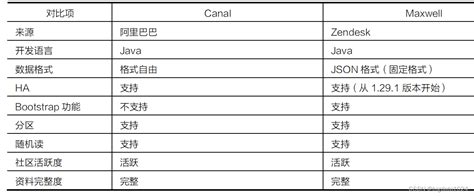
数据查询与分析组件用于从大规模数据集中提取有用信息,并进行可视化和分析。常用的数据查询与分析组件包括:
数据可视化与报告组件用于将数据转化为可视化图表和报告,帮助用户更直观地理解和分析数据。常见的数据可视化与报告组件包括:
大数据生态环境由多个组件构成,每个组件都发挥着重要的作用,相互配合形成了一个完整的大数据处理系统。选择合适的组件并合理设计架构是保证大数据处理效率和性能的关键。随着大数据技术的不断发展,新的组件和工具不断涌现,我们也需要不断学习和更新技术,以应对日益复杂的数据处理需求。
以上是对大数据生态环境组件的解析与指导建议,希望能对您理解和应用大数据技术有所帮助。
标签: 大数据生态组件有哪些 大数据对生态环境的作用 大数据生态圈组件 生态环境大数据平台 生态环境大数据技术是做什么的
相关文章

打造大数据平台生态圈随着信息化时代的不断发展,大数据已经成为企业发展的重要驱动力之一。打造大数据平台生态圈是企业实现数据资产最大化利用的关键一环。本文...
2024-05-19 347 大数据生态圈组件 大数据平台构建的意义 打造全国统一大数据平台

###生态圈大数据平台:解析与指导建议####1.什么是生态圈大数据平台?生态圈大数据平台是指一个集成了大数据处理、分析和应用的综合性平台,旨在帮助企...
2024-04-21 679 生态环境大数据平台 生态大数据技术 大数据生态圈中不存在flume 平台生态圈收益 大数据平台生命周期