大数据的相关技术架构
大数据架构技术是指用于处理和存储大规模数据的技术体系,它包括数据采集、数据存储、数据处理、数据分析和数据可视化等方面。在大数据时代,传统的数据处理技术已经不能满足大规模数据处理的要求,所以需要借助大数据架构技术来应对。
下面将介绍常用的大数据架构技术及其特点:
1. 分布式文件系统(Distributed File System,DFS):
DFS是大数据处理的基础,它能够将文件切分成多个块,分布到多个存储节点上。这样可以提高数据的存储容量和处理效率,并且保证数据的可靠性和可扩展性。常见的DFS包括Hadoop的HDFS和谷歌的GFS等。
2. 分布式计算框架:
分布式计算框架用于对大规模数据进行并行计算和分布式处理。它可以将复杂的计算任务分解成多个小任务,并行处理。常见的分布式计算框架包括Hadoop的MapReduce、Spark、Flink等。
3. 数据仓库:
数据仓库是一个集成、主题导向的数据存储系统,用于存储和管理大量结构化和半结构化数据。它可以提供高效的数据查询和分析功能,支持复杂的数据模型和查询操作。常见的数据仓库包括Hadoop的Hive、Amazon Redshift等。
4. NoSQL数据库:
NoSQL数据库是一类非关系型、分布式的数据库,适用于大量非结构化和半结构化数据的存储和查询。NoSQL数据库的主要特点是高可扩展性、高性能和灵活的数据模型。常见的NoSQL数据库包括MongoDB、Cassandra、HBase等。
5. 数据流处理:
数据流处理技术用于对实时数据进行快速处理和分析。它可以从实时数据源中提取数据,并进行实时的计算和处理。常见的数据流处理系统包括Storm、Kafka、Spark Streaming等。
在设计大数据架构时,需要考虑以下几个方面:
1. 数据规模和性能需求:
根据数据的规模和处理需求确定合适的存储和处理技术。如果数据量很大,可以选择分布式文件系统和分布式计算框架,以提高性能和可扩展性。
2. 数据安全和隐私:
处理大数据时,需要特别关注数据的安全性和隐私保护。建议采用合适的权限控制机制,确保只有授权的用户可以访问敏感数据。
3. 数据一致性和可靠性:
在分布式环境下,数据一致性和可靠性是关键问题。需要通过数据复制和备份等措施来保证数据的完整性和可靠性。
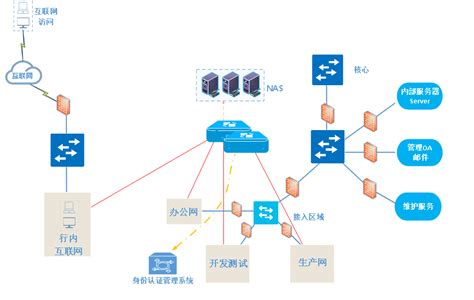
4. 数据集成和交换:
大数据架构需要能够与其他系统进行数据集成和交换。建议采用标准的数据格式和接口,以便与其他系统进行无缝集成。
总结起来,构建一个稳定、可扩展、高性能的大数据架构需要综合考虑数据规模、性能需求、安全性、一致性和数据集成等因素,选择合适的技术和工具。随着大数据技术的不断发展,新的架构技术也在不断涌现,需要及时关注和学习最新的技术趋势。
标签: 描述大数据的4层堆栈式技术架构 简述大数据集群技术的架构 大数据分析技术架构 简述大数据的技术架构
相关文章